VIS, a database on fishes in Flanders, is published as open data
How we used GBIF tools and CC0 to publish over 400,000 fish occurrences.
Introduction
In addition to the new infrastructure we are setting up for our terrestrial and freshwater observatory, we are also integrating existing systems of the INBO into the LifeWatch infrastructure. As the majority of our systems contain species occurrence data, we are making use of GBIF tools to standardize, document, and publish our data. One of the systems1 that we have just made available in such a way is the Fish Information System (VIS), releasing more than 400,0002 fish occurrences as two datasets into the public domain, where they can be used by anyone.
Background
The Fish Information System is a database set up by the INBO to monitor the status of fishes and their habitats in Flanders, Belgium. It contains data regarding occurrences, stocks, pollutants, indexes, and reintroductions. The consolidated database was set up in 2001, but sampling has been going on since 1992. The data are used to calculate the EQR (Ecological Quality Ratio) in the framework of the EU water directive and Natura2000, as well as to provide updated information for the Flemish red list of freshwater fishes.
Although summarized data are publicly accessible to users via vis.inbo.be, these cannot be accessed via a webservice and do not meet the criteria for open data we strive for.
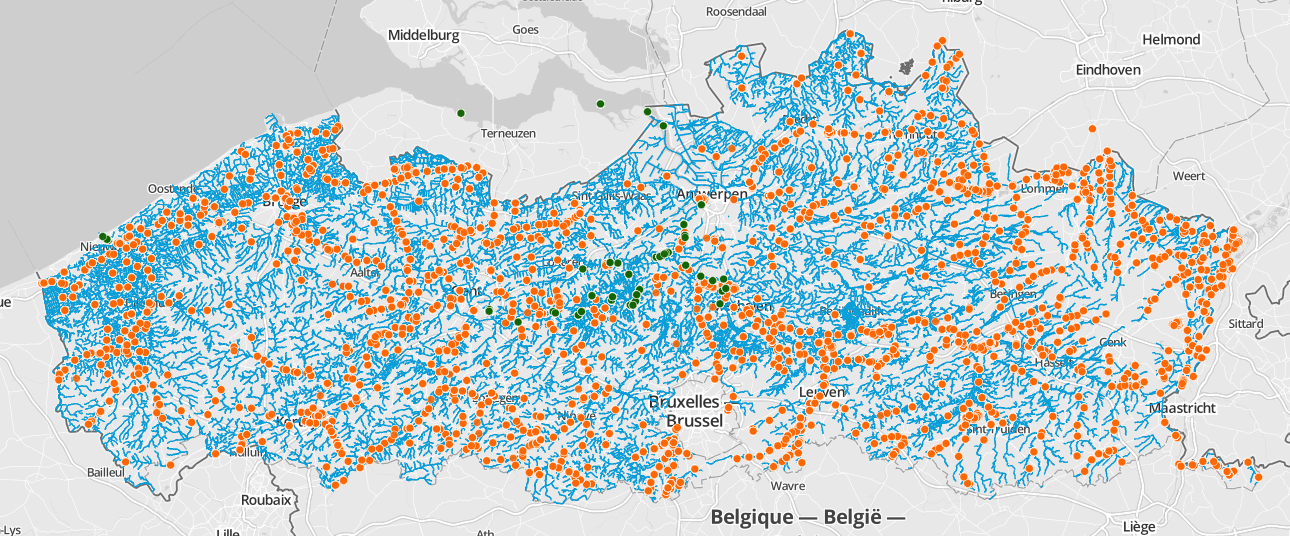 Map of the all the sampling locations in VIS (orange = inland waters, green = estuarine waters).
Map of the all the sampling locations in VIS (orange = inland waters, green = estuarine waters).
Publishing data using GBIF tools
In collaboration with Dimitri Brosens from the Belgian Biodiversity Platform and the involved researchers, we published the data as two datasets: one for inland waters and one for estuarine waters.
For each dataset we created an SQL view in the VIS database, expressing all species occurrence information as Darwin Core terms. Darwin Core is the international standard for expressing biodiversity data. This view is then used by our GBIF Integrated Publishing Toolkit (IPT) to serve the data as a tab-delimited text file.
In addition, we described the datasets in detail. These metadata are recorded in our IPT in the Ecological Metadata Language (EML), the international standard for expressing such information. The metadata include information regarding the project, involved parties, sampling methods, and taxonomic, geographic, and temporal scope.
Both data and metadata are then published as a Darwin Core Archive, a zipped folder containing the standardized files3. Darwin Core Archives are the recommended method for disclosing biodiversity data in bulk, allowing users and machines to download, read, and use the data and metadata. Updates to the data are published regularly to our IPT, as new versions of the same Darwin Core Archive.
To increase discoverability4, we registered the datasets with the Global Biodiversity Information Facility (GBIF). This not only allows users to discover the data, but also allows machines to interface with the data and metadata via the robust webservices developed by GBIF.
Open data
The researchers have dedicated the datasets to the public domain under a Creative Commons Zero waiver, allowing anyone to use the data without restrictions. By providing the data under such a waiver and in bulk (i.e. the Darwin Core Archive), these now meet all the criteria for open data. Visit the dataset pages to discover and download the data yourself:
- VIS - Fishes in inland waters in Flanders, Belgium (359,262 records)
- VIS - Fishes in estuarine waters in Flanders, Belgium (44,694 records)
-
Florabank1, one of our other systems, has been available since August 2011. It currently holds over 3.5 million plant occurrence records. ↩
-
This was incorrectly reported as 440.000 records before. The inflated number of occurrence records was caused by a import issue in the estuarine dataset. ↩
-
You download these files directly from our IPT: Fishes in inland waters (6MB) & Fishes in estuarine waters (1.2MB) ↩
-
Since the registration of the first dataset, the dataset has already generated 120 downloads in the last 3.5 months, covering 25.861.296 records (71 times the size of the dataset). ↩